Overview
Documentation for Reva
Reva is your all-in-one MLOps toolkit designed to streamline the journey from raw data to production-ready AI. Acting as your "personal AI trainer," Reva simplifies the complex stages of model development, allowing you to focus on results rather than infrastructure.
Core Capabilities
- Unified Data Management: Centralize your projects and datasets in one place, ensuring a clean and organized foundation for your AI models.
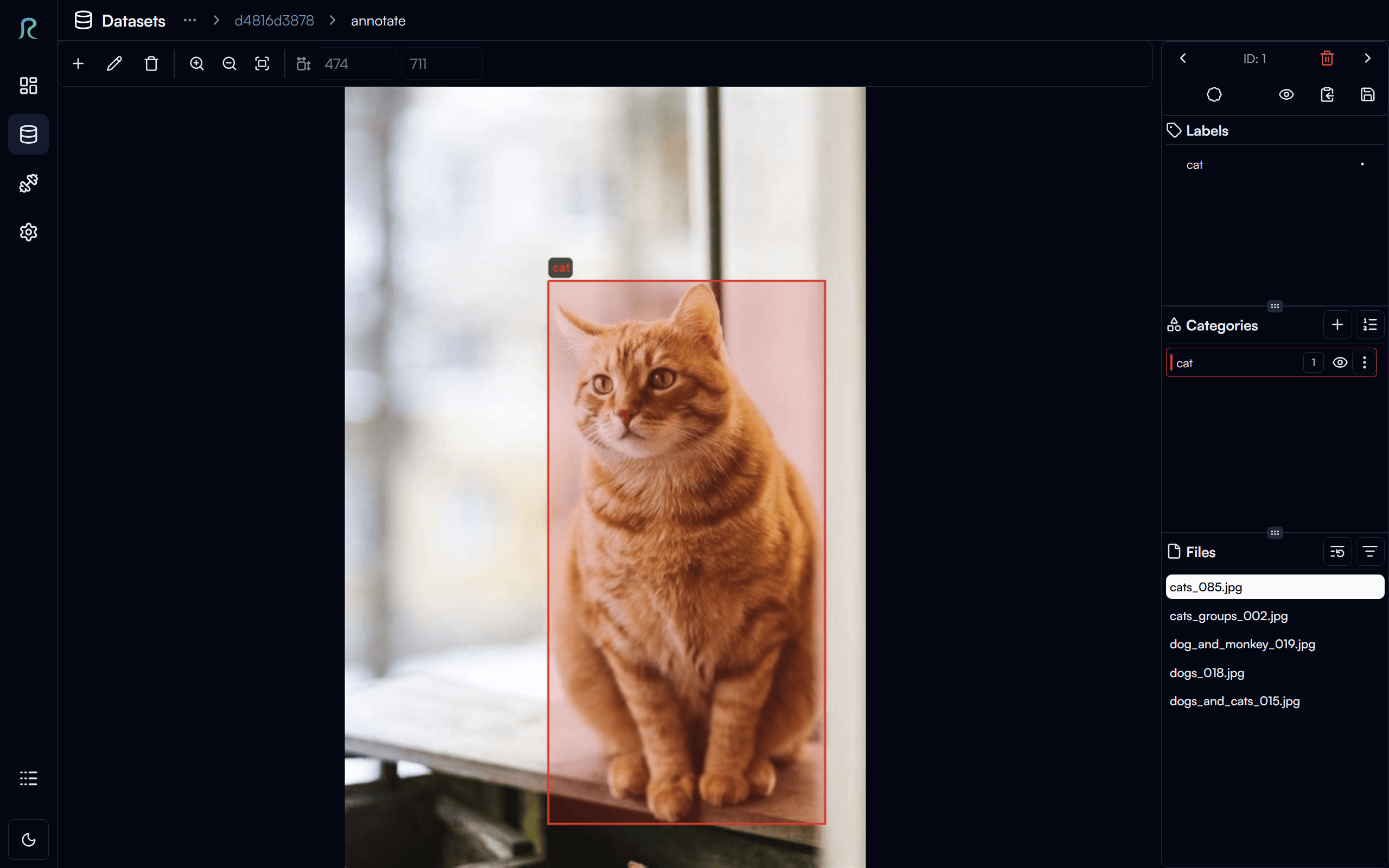
- Precision Annotation: Utilize built-in labeling tools to prepare high-quality training data efficiently, reducing the bottleneck of manual data entry.
- Automated Training: Optimize your models with streamlined training pipelines and hyperparameter tuning to achieve peak performance for specific use cases.
The Development Pipeline
The platform is built to handle the heavy lifting of the machine learning lifecycle through three key phases:
1. Dataset Engineering
Manage the full data lifecycle before the model ever starts learning.
- Annotation Tools: Flexible tools for drawing bounding boxes, polygons, and classification tags.
- Project Management: Track dataset versions and maintain data integrity across multiple team members or projects.
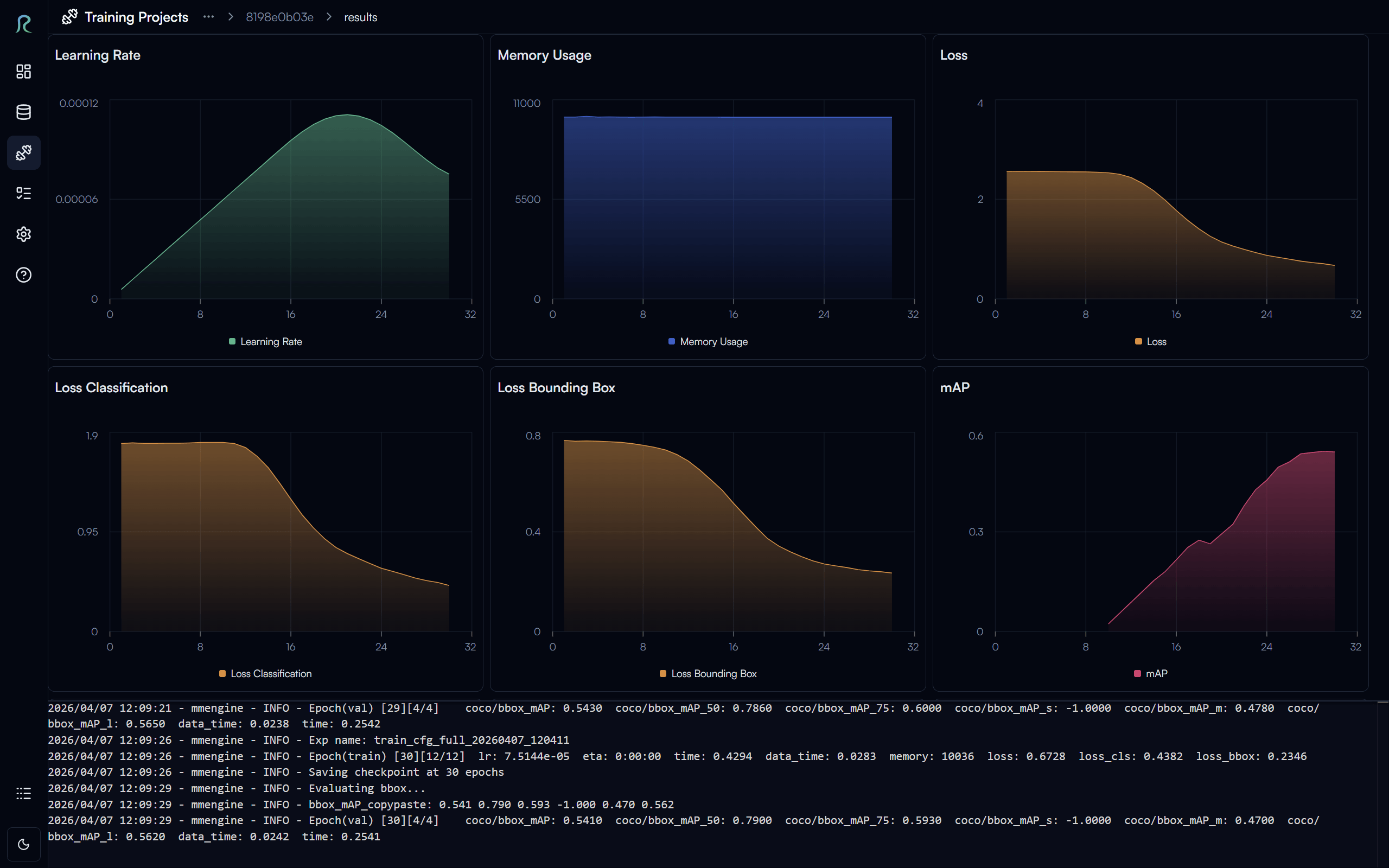
2. Model Training & Optimization
Transform your data into intelligence with high-performance training environments.
- Hyperparameter Tuning: Automatically find the best settings for your model to ensure high accuracy and low latency.
- Resource Efficiency: Optimized training routines designed to produce robust models without unnecessary computational overhead.
3. Seamless Deployment
Reva ensures that once your model is trained, it can actually go to work in the real world.
- Nara Integration: Export directly to the NAM (Nabrio Model) format for instant, "plug-and-play" deployment within Nara.
- Universal Compatibility: Support for industry-standard formats including ONNX, PyTorch, and more, allowing for integration with virtually any AI ecosystem.